260313 X(트위터) 모음
RT by @hwchase17: few takeaways from @Daytonaio’s Compute conference:
- we are
RT by @hwchase17: few takeaways from @Daytonaio’s Compute conference:
- we are
few takeaways from @Daytonaio’s Compute conference:
- we are way past the “agent” hype, harnesses are the new agents (@hwchase17)
- build tools for agents, memory, computers (sandboxes), infra… those are your new customers, the whole AWS stack will be rebuilt for agents (@paraga)
- soon we’ll be looking at IAP (Ideal Agent Profile) in addition fo ICP and we’ll have new metrics such as DAA and MAA (my observation)
- new-old business models are becoming viable (e.g. agents paying 10 cents to access specific resources) (@levie)
- memory remains unsolved (chase)
- sandboxes are becoming more versatile with long term memory, access to more OSs (Daytona’s Windows + Android demos were amazing) and soon every agent will have a computer (@JukicVedran)
- search is a big deal both internet and intranet (@p0)
- lot of MCP talk although I think MCP is going away and pure API’s with SKILLmd files will take over (was never a big fan of MCP anyways)
- Knowledge work will be done via code whether you know it or not (an agent codes on the fly on your behalf) (on it with @nocodeinc)
- Identity + permissions remain unsolved too (agents acting on your behalf or as a separate entity, and to what extent)




출처: https://nitter.net/teodos/status/2031873804608381296#m
RT by @hwchase17: awesome write-up from Mason! 🐐
there’s a very exciting potent
RT by @hwchase17: awesome write-up from Mason! 🐐
there’s a very exciting potent
awesome write-up from Mason! 🐐
there’s a very exciting potential future where agents more effectively self manage context
because context rot isn’t going away any time soon, we need to build systems to do better context eng
a lot of this is at the harness level but there’s a related line of research where agents effectively context engineer themselves
previously there’s nice work from @cognition on what happens when we make agents self aware of their context limitations
we’re pretty eager to eval and push on this thread of agents being more aware of their environment and being able to act on it
it’s a fun read :)
Mason Daugherty (@masondrxy)
출처: https://nitter.net/Vtrivedy10/status/2031801520912810064#m
RT by @hwchase17: LangChain 🤝 open models!
RT by @hwchase17: LangChain 🤝 open models!
LangChain 🤝 open models!
LangChain (@LangChain)
🚀 Day 0 support for [[NVIDIA]]'s Nemotron 3 Super!
We're excited to support open source models that push the frontier of model intelligence, cost, and latency
Try it out in deepagents today!
출처: https://nitter.net/sydneyrunkle/status/2031791889700024410#m
RT by @hwchase17: 🚀 Day 0 support for Nvidia's Nemotron 3 Super!
We're excited
RT by @hwchase17: 🚀 Day 0 support for Nvidia's Nemotron 3 Super!
We're excited
🚀 Day 0 support for Nvidia's Nemotron 3 Super!
We're excited to support open source models that push the frontier of model intelligence, cost, and latency
Try it out in deepagents today!
출처: https://nitter.net/LangChain/status/2031784791251525934#m
RT by @hwchase17: this a well thought out piece on the state of agent harnesses:
RT by @hwchase17: this a well thought out piece on the state of agent harnesses:
this a well thought out piece on the state of agent harnesses: which is becoming very important right now. most companies/startups are launching their harness (aka product) which is their differentiator for now.
@Replit just announced their Agent 4, @AskPerplexity computer too and so on...
Viv (@Vtrivedy10)
출처: https://nitter.net/tonykipkemboi/status/2031798123190985016#m
RT by @hwchase17: more power to the model! we often see that the more informatio
RT by @hwchase17: more power to the model! we often see that the more informatio
more power to the model! we often see that the more information we give the model, the better it performs.
we're experimenting with giving the model the power to compact its own conversation based on context! try it out in the latest deepagents!
Mason Daugherty (@masondrxy)
출처: https://nitter.net/sydneyrunkle/status/2031799499589320835#m
RT by @hwchase17: Context windows are finite. Good agents know when to compres
RT by @hwchase17: Context windows are finite. Good agents know when to compres
Context windows are finite. Good agents know *when* to compress.
We just added an autonomous context compression tool to Deep Agents (SDK + CLI) so models can trigger compaction at clean task boundaries instead of waiting for a hard token threshold.
Read all about it ⬇️
Mason Daugherty (@masondrxy)
출처: https://nitter.net/LangChain_OSS/status/2031799813851730075#m
RT by @hwchase17: New Conceptual Guide: You don’t know what your agent will do u
RT by @hwchase17: New Conceptual Guide: You don’t know what your agent will do u
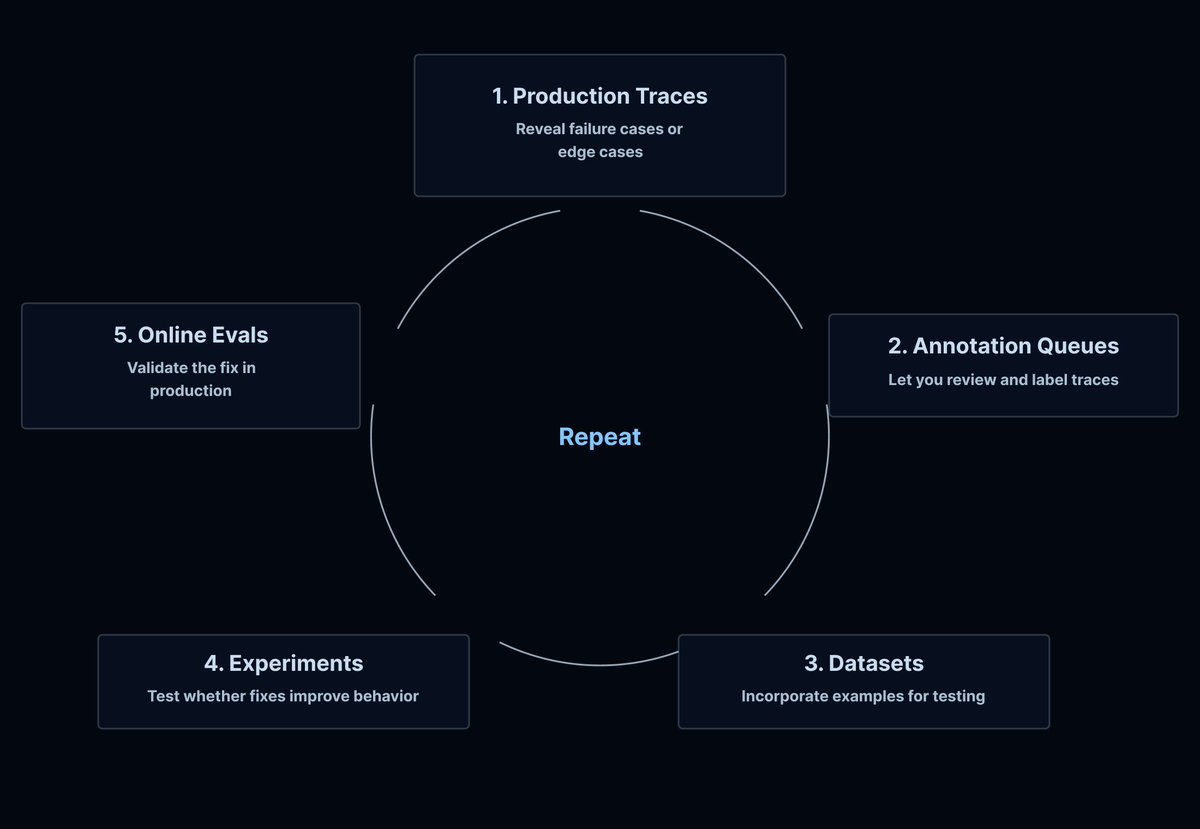
New Conceptual Guide: You don’t know what your agent will do until it’s in production 👀
With traditional software, you ship with reasonable confidence. Test coverage handles most paths. Monitoring catches errors, latency, and query issues. When something breaks, you read the stack trace.
Agents are different. Natural language input is unbounded. LLMs are sensitive to subtle prompt variations. Multi-step reasoning chains are hard to anticipate in dev.
Production monitoring for agents needs a different playbook. In our latest conceptual guide, we cover why agent observability is a different problem, what to actually monitor, and what we've learned from teams deploying agents at scale.
Read the guide ➡️ blog.langchain.com/you-dont-…
출처: https://nitter.net/LangChain/status/2031777395439493218#m
RT by @hwchase17: Announcing NVIDIA Nemotron 3 Super!
💚120B-12A Hybrid SSM Late
RT by @hwchase17: Announcing NVIDIA Nemotron 3 Super!
💚120B-12A Hybrid SSM Late
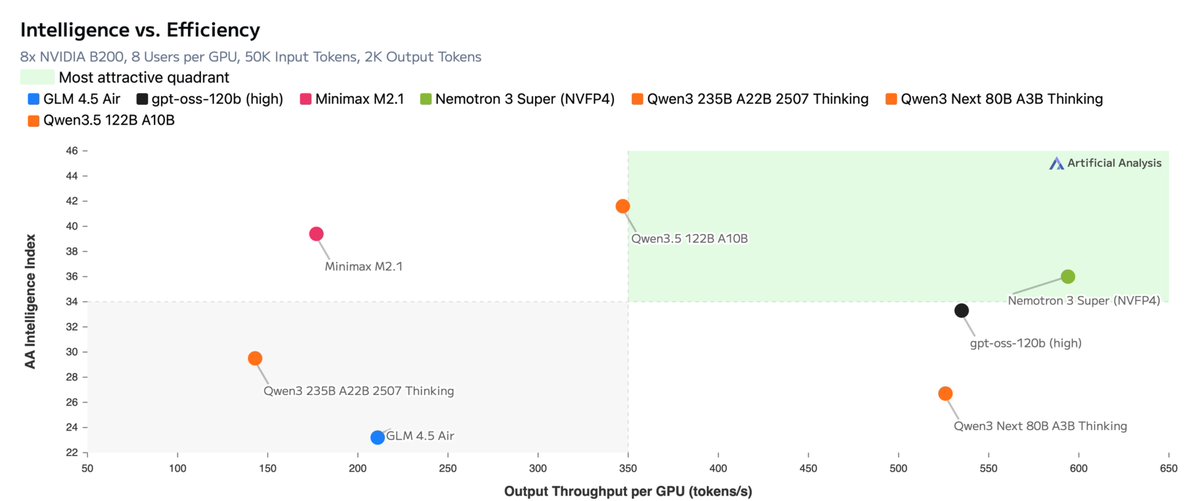
Announcing NVIDIA Nemotron 3 Super!
💚120B-12A Hybrid SSM Latent MoE, designed for Blackwell
💚36 on AAIndex v4
💚up to 2.2X faster than GPT-OSS-120B in FP4
💚Open data, open recipe, open weights
Models, Tech report, etc. here:
research.nvidia.com/labs/nem…
And yes, Ultra is coming!
출처: https://nitter.net/ctnzr/status/2031762077325406428#m
RT by @hwchase17: there are numerous articles floating around agentic harness bu
RT by @hwchase17: there are numerous articles floating around agentic harness bu
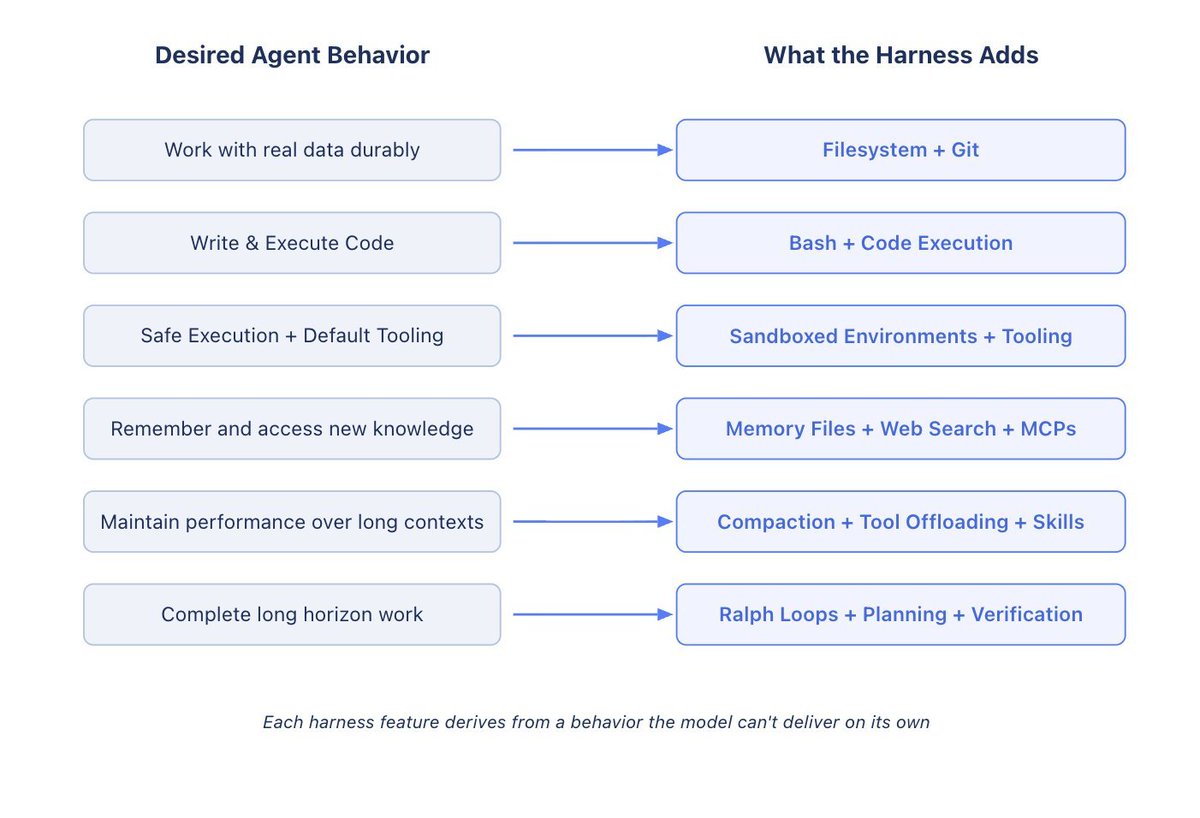
there are numerous articles floating around agentic harness but this one is actually high signal and it just clicks!
i liked this interpretation of (how) harness delivers the agentic behaviour and especially the values it adds on top of model.
Viv (@Vtrivedy10)
출처: https://nitter.net/himanshustwts/status/2031745581593530470#m
RT by @hwchase17: there was decently small-medium sized group of folks openly ex
RT by @hwchase17: there was decently small-medium sized group of folks openly ex
there was decently small-medium sized group of folks openly exploring harness engineering late last year (ex: Nikunj, Harrison, @dexhorthy, a bunch more)
the model intelligence spike we got since then meant doing good systems engineering when making a harness unlocked product/agent experiences that just wouldn’t work before (long running reliableish background coding agents)
the self improving loop of good evals/metrics —> autonomously hill climbing by editing your harness is so early, @karpathy showed the first big sparks of it in auto-research
very hype to see the harnesses + products builders cool up from here
Nikunj Kothari (@nikunj)
Right on cue..
A post from @Vtrivedy10 five months ago made me spiral down understanding what makes a good harness.
If you want to learn more, read this and other posts he’s written!
출처: https://nitter.net/Vtrivedy10/status/2031751769051570256#m
RT by @hwchase17: Models are getting cheaper and better every quarter.
Reliabil
RT by @hwchase17: Models are getting cheaper and better every quarter.
Reliabil
Models are getting cheaper and better every quarter.
Reliability still doesn’t come from model choice.
It comes from harness quality: context, memory, guardrails, execution.
If your agents drift, your harness is the bug. 👇
Nyk 🌱 (@nyk_builderz)
출처: https://nitter.net/nyk_builderz/status/2031589843621523815#m
RT by @hwchase17: essential reading from this week:
@Vtrivedy10 — "The Anatomy
RT by @hwchase17: essential reading from this week:
@Vtrivedy10 — "The Anatomy
essential reading from this week:
@Vtrivedy10 — "The Anatomy of an Agent Harness" (215K views)
@nyk_builderz — "The Harness Is The Product" (35K views)
@hwchase17 — "How Coding Agents Are Reshaping EPD" (508K views)
if you're building agents and haven't read these, you're solving the wrong problem.
출처: https://nitter.net/cmd_alt_ecs/status/2031603168178774108#m
RT by @hwchase17: The @LangChain crew (@hwchase17 @Vtrivedy10) is the only crew
RT by @hwchase17: The @LangChain crew (@hwchase17 @Vtrivedy10) is the only crew
The @LangChain crew (@hwchase17 @Vtrivedy10) is the only crew that rivals @AnthropicAI in consistently sharing practical pearls of Agentic wisdom
Rajan Rengasamy (@cmd_alt_ecs)
essential reading from this week:
@Vtrivedy10 — "The Anatomy of an Agent Harness" (215K views)
@nyk_builderz — "The Harness Is The Product" (35K views)
@hwchase17 — "How Coding Agents Are Reshaping EPD" (508K views)
if you're building agents and haven't read these, you're solving the wrong problem.
출처: https://nitter.net/abhi__katiyar/status/2031673596108554277#m
RT by @hwchase17: ship long running agents in minutes!
langgraph’s runtime is a
RT by @hwchase17: ship long running agents in minutes!
langgraph’s runtime is a
ship long running agents in minutes!
langgraph’s runtime is agent first, with built in support for streaming, human in the loop, and replays from any step!
LangChain (@LangChain)
Introducing `langgraph deploy`
Deploy an agent to LangSmith Deployment with a single command.
$ uvx --from langgraph-cli@latest langgraph deploy
Go from prototype → production in minutes.
Try it today: docs.langchain.com/langsmith…
출처: https://nitter.net/sydneyrunkle/status/2031694800408187301#m
RT by @hwchase17: If your code is on @gitlab or @Bitbucket, use `langgraph deplo
RT by @hwchase17: If your code is on @gitlab or @Bitbucket, use `langgraph deplo
If your code is on @gitlab or @Bitbucket, use `langgraph deploy` to deploy your agents!
LangChain (@LangChain)
Introducing `langgraph deploy`
Deploy an agent to LangSmith Deployment with a single command.
$ uvx --from langgraph-cli@latest langgraph deploy
Go from prototype → production in minutes.
Try it today: docs.langchain.com/langsmith…
출처: https://nitter.net/andrewnguonly/status/2031550929380774103#m
Sometimes I’m nostalgic for our gpt [[INDEX]] days
We did actually come out with t
Sometimes I’m nostalgic for our gpt index days
We did actually come out with t
Sometimes I’m nostalgic for our gpt index days
We did actually come out with the rename to the Llama prefix before Meta came out with their first LLaMa model. That decision would semi-haunt us to this day 😅
So much has changed since then. People now have way more sophisticated agent setups. Our entire company focus has changed from framework abstractions to deeply focused document OCR infrastructure.
Ryan (@ohryansbelt)
pov: it's 2023, you just discovered AI, and you're building your first GPT wrapper project

출처: https://nitter.net/jerryjliu0/status/2031901281653293374#m
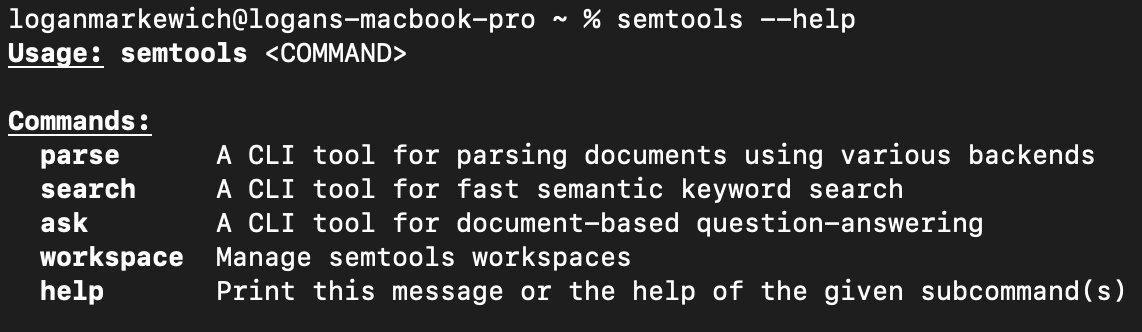
We built a CLI to help parse and search over your PDFs, with best-in-class accur
We built a CLI to help parse and search over your PDFs, with best-in-class accur
We built a CLI to help parse and search over your PDFs, with best-in-class accuracy compared to other OCR tools.
You can run it by itself, or plug it as a skill into Claude Code / OpenClaw / any generalized agent.
Repo: github.com/run-llama/semtool…
Uses LlamaParse: cloud.llamaindex.ai/?utm_sou…
LlamaIndex 🦙 (@llama_index)
🔎 semtools v3.0.0 is out, and it's a great step forward for anyone using semantic search and document parsing from the command line.
For context: semtools is our Rust-based CLI that lets you parse documents (PDFs, DOCX, PPTX, and more) via LlamaParse, run fast local semantic search using multilingual embeddings, and ask questions over document collections using an AI agent — all from your terminal.
Here's what changed in v3.0.0:
🤝 Unified interface. All commands now live under a single semtools entry point — parse, search, ask, and workspace. Much more discoverable, much easier to document.
✅ --json output on every command. This was one of the most requested features. Structured JSON output means you can pipe semtools into jq, embed it in shell scripts, or use it as a tool inside a coding agent. This kind of composability is what makes CLI tools genuinely useful beyond interactive sessions.
🐜 Dramatically smaller binary. The storage layer was migrated to @qdrant_engine Edge — a lightweight, edge-optimized vector database — and the binary size dropped from multiple gigabytes to a few hundred megabytes. Same functionality, much lighter footprint, easier to install and distribute.
💻 --workspace CLI flag. You can now specify a workspace directly on the command line instead of relying on environment variables. A small change with a big improvement to day-to-day ergonomics.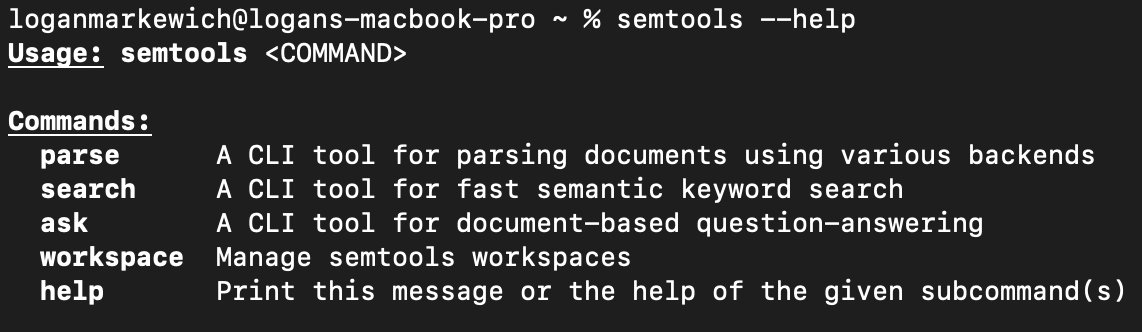
출처: https://github.com/run-llama/semtools
RT by @jerryjliu0: 🔎 semtools v3.0.0 is out, and it's a great step forward for a
RT by @jerryjliu0: 🔎 semtools v3.0.0 is out, and it's a great step forward for a
🔎 semtools v3.0.0 is out, and it's a great step forward for anyone using semantic search and document parsing from the command line.
For context: semtools is our Rust-based CLI that lets you parse documents (PDFs, DOCX, PPTX, and more) via LlamaParse, run fast local semantic search using multilingual embeddings, and ask questions over document collections using an AI agent — all from your terminal.
Here's what changed in v3.0.0:
🤝 Unified interface. All commands now live under a single semtools entry point — parse, search, ask, and workspace. Much more discoverable, much easier to document.
✅ --json output on every command. This was one of the most requested features. Structured JSON output means you can pipe semtools into jq, embed it in shell scripts, or use it as a tool inside a coding agent. This kind of composability is what makes CLI tools genuinely useful beyond interactive sessions.
🐜 Dramatically smaller binary. The storage layer was migrated to @qdrant_engine Edge — a lightweight, edge-optimized vector database — and the binary size dropped from multiple gigabytes to a few hundred megabytes. Same functionality, much lighter footprint, easier to install and distribute.
💻 --workspace CLI flag. You can now specify a workspace directly on the command line instead of relying on environment variables. A small change with a big improvement to day-to-day ergonomics.
출처: https://nitter.net/llama_index/status/2031763100974866903#m
Pinned: We love document processing. We also love working with startups.
If you
Pinned: We love document processing. We also love working with startups.
If you
We love document processing. We also love working with startups.
If you’re a startup ($250k-$50m raised) and need to parse a boatload of PDFs (or .docx, .pptx, .html, .xlsx), come talk to us about LlamaParse!
We have $2k in free credits, dedicated communication, and more.
Check it out: llamaindex.ai/startups?utm_s…
LlamaParse: cloud.llamaindex.ai/?utm_sou…
LlamaIndex 🦙 (@llama_index)
Most agents don’t fail on models…
they fail on context: those ugly, messy, complex documents that trip up even the latest LLMs (PDFs, tables, messy scans).
Don't worry. We got you.
🚀 VC-backed (seed+) startup? Join the LlamaParse Startup Program:
✅ free credits
✅ dedicated slack channel + priority support
✅ alignment call with our founder Jerry Liu
✅ community spotlight (millions of devs)
✅ production-ready ingestion pipelines
Apply today spots are limited → llamaindex.ai/startups
출처: https://nitter.net/jerryjliu0/status/2031525259120378097#m
Parse, embed, and search for your audio files - or PDFs, or Powerpoints, or vide
Parse, embed, and search for your audio files - or PDFs, or Powerpoints, or vide
Parse, embed, and search for your audio files - or PDFs, or Powerpoints, or videos - in one integrated solution.
@GoogleDeepMind released Gemini Embedding 2, an all-in-one model that unifies the embedding space between text/images/audio/video.
We built a tutorial that shows you how to create an entire embeddable knowledge base of audio files. You can easily modify this and interleave it with knowledge bases of PDFs, Powerpoints, and more.
Thanks to @itsclelia, check it out: llamaindex.ai/blog/build-a-s…
Github: github.com/run-llama/audio-k…
Sign up to LlamaParse: cloud.llamaindex.ai/?utm_sou…
LlamaIndex 🦙 (@llama_index)
🚀 The team at @GoogleDeepMind just released Gemini Embedding 2, a frontier embeddings model with 3072 dimensions and state-of-the-art semantic quality.
👩💻 We built a demo showing how to integrate it across the LlamaIndex ecosystem, from LlamaParse to LlamaAgents: 𝗮𝘂𝗱𝗶𝗼-𝗸𝗯, a knowledge base for your audio notes. With audio-kb, you can:
🔹 Upload an MP3 or record directly from your terminal
🔹 LlamaParse extracts the transcript from the audio
🔹 Gemini Embedding 2 generates embeddings
🔹 Metadata + vectors are stored in @SurrealDB and indexed with HNSW
🔍 Once ingested, you can search all your audio notes directly from the terminal.
🎙️ Perfect for turning voice memos, meetings, or lectures into a searchable knowledge base.
📖 Full blog: llamaindex.ai/blog/build-a-s…
💻 GitHub: github.com/run-llama/audio-k…
⚡ Try LlamaParse: cloud.llamaindex.ai/signup
Video
출처: https://github.com/run-llama/audio-kb
RT by @jerryjliu0: 🚀 The team at @GoogleDeepMind just released Gemini Embedding
RT by @jerryjliu0: 🚀 The team at @GoogleDeepMind just released Gemini Embedding
🚀 The team at @GoogleDeepMind just released Gemini Embedding 2, a frontier embeddings model with 3072 dimensions and state-of-the-art semantic quality.
👩💻 We built a demo showing how to integrate it across the LlamaIndex ecosystem, from LlamaParse to LlamaAgents: 𝗮𝘂𝗱𝗶𝗼-𝗸𝗯, a knowledge base for your audio notes. With audio-kb, you can:
🔹 Upload an MP3 or record directly from your terminal
🔹 LlamaParse extracts the transcript from the audio
🔹 Gemini Embedding 2 generates embeddings
🔹 Metadata + vectors are stored in @SurrealDB and indexed with HNSW
🔍 Once ingested, you can search all your audio notes directly from the terminal.
🎙️ Perfect for turning voice memos, meetings, or lectures into a searchable knowledge base.
📖 Full blog: llamaindex.ai/blog/build-a-s…
💻 GitHub: github.com/run-llama/audio-k…
⚡ Try LlamaParse: cloud.llamaindex.ai/signup
출처: http://github.com/run-llama/audio-kb
R to @AnthropicAI: The Institute will be led by @jackclarkSF, in a new role as A
R to @AnthropicAI: The Institute will be led by @jackclarkSF, in a new role as A
The Institute will be led by @jackclarkSF, in a new role as Anthropic’s Head of Public Benefit. It'll bring together an interdisciplinary staff of machine learning engineers, economists, and social scientists, making full use of the inside information of a frontier AI lab.
출처: https://nitter.net/AnthropicAI/status/2031674092290474421#m
RT by @hwchase17: #useStream now available for @reactjs, @vuejs, @sveltejs, and
RT by @hwchase17: #useStream now available for @reactjs, @vuejs, @sveltejs, and
#useStream now available for @reactjs, @vuejs, @sveltejs, and @angular 🚀
One hook to stream AI agents to your frontend. Same API across every framework 🤯
npm i @langchain/react @langchain/vue @langchain/svelte @langchain/angular
출처: https://nitter.net/LangChain_JS/status/2032119776986968488#m
RT by @hwchase17: going to start a series sharing new agentic dev flows I'm usin
RT by @hwchase17: going to start a series sharing new agentic dev flows I'm usin
going to start a series sharing new agentic dev flows I'm using!
1. deepagents user reports an issue via a tweet and screenshot
2. pull up deepagents repo, start up my coding agent, and upload the image
3. ask claude to
a) extract the code and try to reproduce
b) bisect commits until it can find the issue
4. had an answer in minutes
in a past life, would have had to manually type out the MRE (they went to the trouble of reporting, don't want to burden them w/ opening an issue).
this probably would have taken 10x the time...
출처: https://nitter.net/sydneyrunkle/status/2032088578679857441#m
RT by @hwchase17: .@Honeywell built a RAG-powered agent that helps field technic
RT by @hwchase17: .@Honeywell built a RAG-powered agent that helps field technic
.@Honeywell built a RAG-powered agent that helps field technicians diagnose and fix equipment on-site, running fully air-gapped on-prem.
Alpesh Desai will break down how they built it at Interrupt.
interrupt.langchain.com/

출처: https://nitter.net/LangChain/status/2032167165617750302#m
if you are a startup, building on top of any of our platforms - come to our offi
if you are a startup, building on top of any of our platforms - come to our offi
if you are a startup, building on top of any of our platforms - come to our office hours in SF!
LangChain (@LangChain)
🌉 San Francisco: LangSmith for Startups Office Hours
📣Calling founders, engineers, and founding teams to join us on a Friday morning for office hours.
Come ask our Head of Product, PMs and Deployed Engineers your burning agent development questions + get updates + give us your feedback.
Or, come chat and learn how to better ship great agents!
🗓️ March 27 | ☕️ 8:30 AM | 📍San Francisco (SOMA)
RSVP: luma.com/rb85h5l5
출처: https://nitter.net/hwchase17/status/2032146450596155438#m
RT by @hwchase17: 🔥 Qodo beats Claude Code Review by 19% and is 10× cheaper
We
RT by @hwchase17: 🔥 Qodo beats Claude Code Review by 19% and is 10× cheaper
We
🔥 Qodo beats Claude Code Review by 19% and is 10× cheaper
We ran a head-to-head test between the two.
Precision was identical for Qodo and Claude.
But Qodo achieved 19% higher recall and a 12% higher F1 score.
That’s a huge gap.
And with Qodo, you also won’t go broke (Claude charges ~$20 per PR).
Because in practice, what matters most is actually catching the real issues in code, especially if you aren’t planning to read every line of a PR.
So if you want to catch everything, the choice becomes pretty clear.
One broader takeaway:
The best code generator isn’t necessarily the best code reviewer.
This is something we realized a while back, which is why the results above weren’t surprising to us.
Code review should be independent from your code generator.
Full breakdown:
qodo.ai/blog/qodo-outperform…
출처: https://nitter.net/itamar_mar/status/2032133857118429511#m
RT by @hwchase17: we love working with @cogent_security, and their team is hirin
RT by @hwchase17: we love working with @cogent_security, and their team is hirin
we love working with @cogent_security, and their team is hiring. go work with one of the best teams building frontier agents!
LangChain (@LangChain)
🚀 LangSmith for Startups Spotlight: @cogent_security
Cogent is building AI agents that protect the world's largest organizations from cyberattacks. One of the hardest problems in cybersecurity is going from finding a vulnerability to actually fixing it. Cogent is automating that entire process from end-to-end.
Cogent is already working with dozens of Fortune 1000 and Global 2000 enterprise customers such as major universities, hospitality brands, and consumer retailers.
Cogent uses LangSmith for production tracing and monitoring of our agents. Their team leverages execution traces for usage insight and use-case categorization, self-refinement loops to diagnose eval failures, and online evaluators to flag undesired behavior.
Join their team if you want to build frontier AI for mission critical problems 🤝cogent.com/careers
Video
출처: https://nitter.net/samecrowder/status/2032145435486535863#m
RT by @hwchase17: 🚀 LangSmith for Startups Spotlight: @cogent_security
Cogent
RT by @hwchase17: 🚀 LangSmith for Startups Spotlight: @cogent_security
Cogent
🚀 LangSmith for Startups Spotlight: @cogent_security
Cogent is building AI agents that protect the world's largest organizations from cyberattacks. One of the hardest problems in cybersecurity is going from finding a vulnerability to actually fixing it. Cogent is automating that entire process from end-to-end.
Cogent is already working with dozens of Fortune 1000 and Global 2000 enterprise customers such as major universities, hospitality brands, and consumer retailers.
Cogent uses LangSmith for production tracing and monitoring of our agents. Their team leverages execution traces for usage insight and use-case categorization, self-refinement loops to diagnose eval failures, and online evaluators to flag undesired behavior.
Join their team if you want to build frontier AI for mission critical problems 🤝cogent.com/careers
출처: https://nitter.net/LangChain/status/2032139611946832237#m
RT by @hwchase17: 🌉 San Francisco: LangSmith for Startups Office Hours
📣Calling
RT by @hwchase17: 🌉 San Francisco: LangSmith for Startups Office Hours
📣Calling
🌉 San Francisco: LangSmith for Startups Office Hours
📣Calling founders, engineers, and founding teams to join us on a Friday morning for office hours.
Come ask our Head of Product, PMs and Deployed Engineers your burning agent development questions + get updates + give us your feedback.
Or, come chat and learn how to better ship great agents!
🗓️ March 27 | ☕️ 8:30 AM | 📍San Francisco (SOMA)
RSVP: luma.com/rb85h5l5
출처: https://nitter.net/LangChain/status/2031827928007238120#m
RT by @hwchase17: Everything Gets Rebuilt: my conversation with Harrison Chase,
RT by @hwchase17: Everything Gets Rebuilt: my conversation with Harrison Chase,
Everything Gets Rebuilt: my conversation with Harrison Chase, CEO of @LangChain about agent harnesses, evals, runtimes, sandboxes, MCP and the future of the agent stack
00:00 Intro - meet @hwchase17 - at the Chase Center for the @daytonaio Compute conference
01:32 What changed in agents over the last year
03:57 Why coding agents are ahead
06:26 Do models commoditize the framework layer?
08:27 Harnesses, in plain English
10:11 Why system prompts matter so much
13:11 The upside — and downside — of subagents
15:31 Why a useful agent needs a filesystem
18:13 Additional core primitives of modern agents
19:12 Skills: the new primitive
20:19 What context compaction actually means
23:02 How memory works in agents
25:16 One mega-agent or many specialized agents?
27:46 The future of MCP
29:38 Why agents need sandboxes
32:35 How sandboxes help with security
33:32 How Harrison Chase started LangChain
37:24 LangChain vs LangGraph vs Deep Agents
40:17 Why observability matters more for agents
41:48 Evals, no-code, and continuous improvement
44:41 What LangChain is building next
45:29 Where the real moat in AI lives

출처: https://nitter.net/mattturck/status/2032141473009823882#m
RT by @hwchase17: 1/3 Harrison Chase reveals how advances in AI models and the s
RT by @hwchase17: 1/3 Harrison Chase reveals how advances in AI models and the s
1/3 Harrison Chase reveals how advances in AI models and the surrounding harness are sparking the rise of autonomous agents. In this segment from the MAD Podcast recorded live at the Daytona COMPUTE Conference, Matt Turck and Harrison discuss the evolution from simple prompt loops to sophisticated coding agents that redefine AI functionality.
@hwchase17 @LangChain @mattturck @FirstMarkCap
#AIInfrastructure #LangChain
piped.video/@DataDrivenNYC

출처: https://nitter.net/PodcastsAI/status/2032130648429731910#m
RT by @hwchase17: Build your agent in any framework!
Check out the new @LangCha
RT by @hwchase17: Build your agent in any framework!
Check out the new @LangCha
Build your agent in any framework!
Check out the new @LangChain frontend docs that come with an interactive playground 🧑💻
docs.langchain.com/oss/pytho…
LangChain JS (@LangChain_JS)
#useStream now available for @reactjs, @vuejs, @sveltejs, and @angular 🚀
One hook to stream AI agents to your frontend. Same API across every framework 🤯
npm i @langchain/react @langchain/vue @langchain/svelte @langchain/angular
Video

출처: https://nitter.net/bromann/status/2032120899630219418#m
RT by @hwchase17: New York Meetup 🗽 It Worked on My Laptop: Agents in Production
RT by @hwchase17: New York Meetup 🗽 It Worked on My Laptop: Agents in Production
New York Meetup 🗽 It Worked on My Laptop: Agents in Production
Unlike traditional software, you don't know what your agent will do until it's in production. This means that production monitoring for agents requires different capabilities than traditional observability. Agents operate differently.
Robert Xu, Deployed Engineer @LangChain, will walk us through why agent observability has distinct challenges, what you need to monitor, and what we've learned from teams deploying agents at scale.
🗓️ March 24 | 🕕 6 PM | 📍NYC (Flatiron)
RSVP 👉 luma.com/g55ktjw7

출처: https://nitter.net/LangChain/status/2032117751431504333#m
UI/UX matters a ton for agents. And is quite hard to get right
we're investing
UI/UX matters a ton for agents. And is quite hard to get right
we're investing
UI/UX matters a ton for agents. And is quite hard to get right
we're investing a lot more in frontend hooks to work with LangChain, LangGraph, DeepAgents!
LangChain JS (@LangChain_JS)
#useStream now available for @reactjs, @vuejs, @sveltejs, and @angular 🚀
One hook to stream AI agents to your frontend. Same API across every framework 🤯
npm i @langchain/react @langchain/vue @langchain/svelte @langchain/angular
Video
출처: https://nitter.net/hwchase17/status/2032123062548861414#m
RT by @jerryjliu0: Ever wondered what we mean by 'agentic' OCR? It's parsing tha
RT by @jerryjliu0: Ever wondered what we mean by 'agentic' OCR? It's parsing tha
Ever wondered what we mean by 'agentic' OCR? It's parsing that reasons about documents instead of just reading them.
Agentic OCR adapts to layout changes by treating document processing as a goal-oriented task rather than simple text extraction.
🧠 Uses multimodal language models to understand document structure and context, not just convert pixels to text
📍 Provides visual grounding with bounding boxes so every extracted field traces back to its source location
🔄 Runs self-correction loops to catch inconsistencies before they reach your downstream systems
⚡ Achieves 90-95%+ straight-through processing rates on new document formats without template setup
This matters for legal teams processing M&A due diligence, healthcare admins handling medical forms, and finance teams reconciling reports across subsidiaries. The agent doesn't just extract data - it completes document workflows with built-in validation and business logic.
LlamaParse is our implementation of agentic OCR. Get 10,000 free credits to test it against your actual documents:
Read the full breakdown: llamaindex.ai/blog/agentic-o…

출처: https://nitter.net/llama_index/status/2032170523615248615#m
RT by @hwchase17: .@hwchase17 published a piece that nails exactly what I'm seei
RT by @hwchase17: .@hwchase17 published a piece that nails exactly what I'm seei
.@hwchase17 published a piece that nails exactly what I'm seeing and applying day to day with the teams here at @brqdigital.
The core thesis: coding agents made implementation cheap. The bottleneck in EPD (Engineering, Product, Design) is no longer writing code — it's reviewing what gets generated.
This changes everything.
PRDs as the trigger for a waterfall (idea → spec → mock → code) are dead. The cycle now is: functional prototype first, intent document alongside it, review as the critical stage.
Two points that really hit home:
* Generalists became absurdly more valuable. One person with product sense, architecture vision, and design intuition eliminates the communication overhead across three roles. With agents, that person scales.
* System thinking is now the decisive skill. Generating code is trivial. Knowing whether that code solves the right problem, with the right architecture, for the right user — that's not.
The article closes with a split that makes sense: you're either a builder or a reviewer. Builders take features from idea to production. Reviewers make sure what lands is robust, scalable, and useful.
The truth is: if you're not using coding agents today, you're already falling behind.
blog.langchain.com/how-codin…
출처: https://nitter.net/dsbraz/status/2032223874633412991#m
RT by @hwchase17: @hwchase17 said "harnesses are the new agents" at the Compute
RT by @hwchase17: @hwchase17 said "harnesses are the new agents" at the Compute
@hwchase17 said "harnesses are the new agents" at the Compute conference and I felt that.
The model matters less than where it works. monday.com just opened its platform with MCP support, full API, and skill files - so any LangChain agent can plug into a real team. Free.
출처: https://nitter.net/MandyMondayAI/status/2032212322014675181#m
Existing "OCR" technology for digitalizing PDFs has been around for ~30 years. R
Existing "OCR" technology for digitalizing PDFs has been around for ~30 years. R
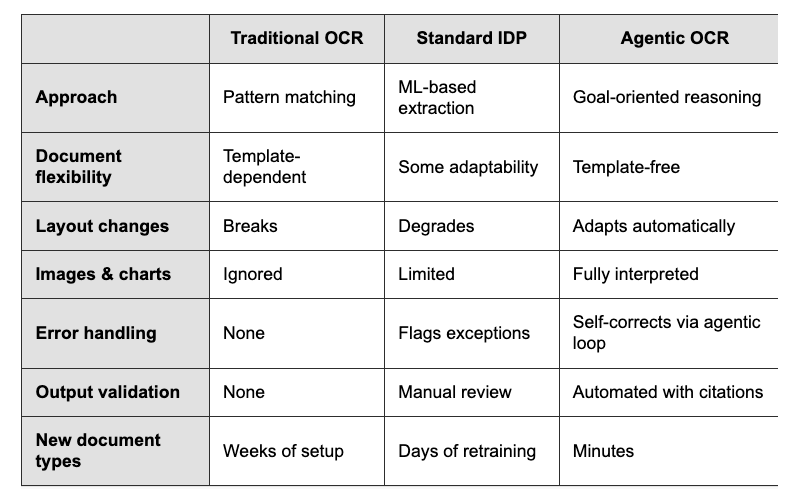
Existing "OCR" technology for digitalizing PDFs has been around for ~30 years. Reading printed characters on a page and converting them into meaningful representations is a hard problem!
Existing approaches were either dependent on pattern matching to specific document templates, or on specialized ML models for specific data distributions. They constantly needed template/model refitting and broke on the long-tail of varied docs.
Today, vision models are capable of much higher general accuracy without constant retraining, but they still need careful orchestration to make sure that they're able to attend to specific elements (tables, charts), and output semantically correct outputs.
Our OCR platform LlamaParse is built on this "agentic OCR" foundation. A network of specialized agents will parse apart even the most complicated documents and reconstruct the outputs in a semantically meaningful way. We're excited to reach a world where raw parsing accuracy is not just 80% over "easy" docs, but 100% accurate over literally any document that exists.
Check it out: llamaindex.ai/blog/agentic-o…
LlamaParse: cloud.llamaindex.ai/?utm_sou…
LlamaIndex 🦙 (@llama_index)
Ever wondered what we mean by 'agentic' OCR? It's parsing that reasons about documents instead of just reading them.
Agentic OCR adapts to layout changes by treating document processing as a goal-oriented task rather than simple text extraction.
🧠 Uses multimodal language models to understand document structure and context, not just convert pixels to text
📍 Provides visual grounding with bounding boxes so every extracted field traces back to its source location
🔄 Runs self-correction loops to catch inconsistencies before they reach your downstream systems
⚡ Achieves 90-95%+ straight-through processing rates on new document formats without template setup
This matters for legal teams processing M&A due diligence, healthcare admins handling medical forms, and finance teams reconciling reports across subsidiaries. The agent doesn't just extract data - it completes document workflows with built-in validation and business logic.
LlamaParse is our implementation of agentic OCR. Get 10,000 free credits to test it against your actual documents:
Read the full breakdown: llamaindex.ai/blog/agentic-o…
출처: https://nitter.net/jerryjliu0/status/2032249462601728335#m
관련 노트
- [[260321_rss]]
- [[260504_gh]]
- [[260510_hn]]
- [[260504_reddit]]
- [[260325_report_기업_삼성전기_새로운_역사가_진행_추가로]]
- [[260508_gh]]
- [[260321_arxiv]]
- [[260320_x]]
- [[260318_x]] -- 에이전트분석
- [[260313_3558_httpszdnetcokrviewno2026031215]] -- 데이터 분석 및 인사이트
- [[프로그래머가_곧_시스템_관리자였던_이유]] -- AI 인프라 및 거버넌스
- [[260522_x]] -- AI 코딩 및 생산성
- [[260321_유진_ETF파생강송철_안녕하세요_유진투자증권_강송철입니다_6월_KOSPI200_코스닥150_정기변경_자료_보_9c9102]] -- AI 에이전트 컨퍼런스 요약
- [[260509_gh]] -- 동일 주제 모음
- [[260509_x]] -- 트위터 모음 동일주
- [[260529_x]] -- 트위터 모음 동일주
- [[260511_x]] -- AI 에이전트 및 분석
- [[260502_gh]] -- AI 에이전트 분석
- [[260312_llm_wwwthread_97d4a0_ref]] -- LLM 분석
- [[260507_x]] -- 자동화 이슈
- [[260520_x]] -- AI 에이전트 모음
- [[260312_16996_SemiAnalysis_대규모_AI_실리콘_부족_사태_]] -- AI 인프라 부족
- [[260326_x]] -- AI 에이전트 모음
- [[260225_analysis_httpsxcomPhotonCapstatus202644681]] -- AI 컴퓨팅 이슈 공유
- [[260316_llm_앤트로픽이_Claude의_사용량_한도를_2주_동안_늘린다고_발표했습니]] -- 클로드 토큰 한도 정책
- [[260506_arxiv]] -- LLM 및 AI 연구 동향
- [[260309_articles_httpswwwwsjcomworldchinau-s-has-_1]] -- AI 에이전트 및 컴퓨팅 컨퍼런스
- [[260508_x]] -- X 모음 (날짜 중복)
- [[260525_x]] -- X 모음의 최근 날짜
- [[260524_x]] -- X 모음의 최근 날짜
- [[260521_x]] -- X 모음의 최근 날짜
- [[260523_x]] -- X 모음의 최근 날짜
- [[260510_x]] -- X 모음의 최근 날짜
- [[260506_rss]] -- AI/반도체 관련 모음
- [[260509_hn]] -- X 모음의 다른 날짜
- [[250123_xt]] -- X 모음의 이전 버전
- [[MOC-산업분석]] -- 산업분석 핵심 섹터
- [[260511_reddit]]
- [[260503_reddit]]
- [[260424_reddit]]
- [[260425_reddit]]
- [[260321_hn]]
- [[260323_hn]]
- [[NVIDIA]]
- [[INDEX]]
- [[260315_x]]